作者:手机用户2502927277 | 来源:互联网 | 2023-09-12 04:37
篇首语:本文由编程笔记#小编为大家整理,主要介绍了Python实战高校数据采集,爬虫训练场项目数据储备相关的知识,希望对你有一定的参考价值。
在制作 爬虫训练场 项目时,需要准备大量的数据,供大家学习使用,本系列博客用于数据储备。
文章目录
本次要采集的是高考大数据,即 2022 年学校排名,数据来源为百度,地址如下。
https://motion.baidu.com/activity/gaokao2022/trend
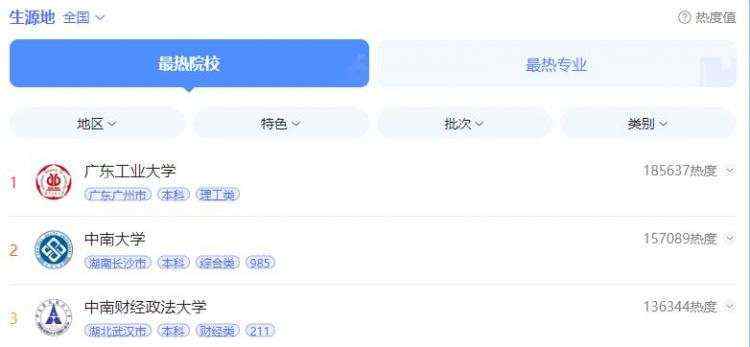
通过开发者工具获取请求接口与请求参数,得到内容如下所示。
- 请求地址:https://motion.baidu.com/gaokao/trendasync?pageSize=30&pageIndex=2
- 请求方法:POST
- 请求头重点参数:
origin:域名referer:上一页地址user-agent:用户代理
- 请求参数:
- 查询参数:pageSize & pageIndex
- 请求载荷:
"source":"全国","tabValue":"campus","filter":,"isScrolling":1
多次测试除 COOKIE 外,无特殊加密参数,并且我们对数据的采集效率无要求,所以可以直接使用 requests 模块对请求进行模拟。
示例代码如下所示
一款普通的 requests 模块爬虫。
import json
import requests
def get_gaokao_data():
headers =
"origin": "https://motion.baidu.com",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/108.0.0.0 Safari/537.36"
data = "source": "全国", "tabValue": "campus", "filter": , "isScrolling": 1
res = requests.post("https://motion.baidu.com/gaokao/trendasync?pageSize=30&pageIndex=0", headers=headers,
data=json.dumps(data))
print(res.text)
if __name__ == '__main__':
get_gaokao_data()
运行代码,可以得到 JSON 格式的响应数据,并且检测到 pageIndex 参数从 0 开始计数,当设置为无限大时,无数据返回,即得到下述格式数据,表示数据已经获取完毕。也可以通过判断 finished 的值判断请求是否结束。
"status":0,"msg":"successful","data":"list":[],"finished":true,"trace":"logid":xxxx
既然已经获取了起始和结尾数据,那我们就可以对爬虫的采集层次进行控制了,通过一个【死循环】抓取数据,当 data/list 为空时,结束采集。
数据入库
上文的示例代码,已经成功采集到 JSON 数据,接下来将其存储到 mysql 数据库中,建表前对响应数据进行格式化操作,核对字段。这里重要的是 data/list 中的数据项。
批次/batchTimes:本科
类别/category:综合类
城市/city:城市
特色/feature:["上海", "本科", "综合类", "985", "211", "双一流", "强基计划", "自主招生"]
热度/hotValue:
学校名/name:同济大学
校徽/pic:`ttps://static-data.eol.cn/upload/logo/73.jpg`
省份/province:"上海"
基于该数据,建立数据表结构如下所示。
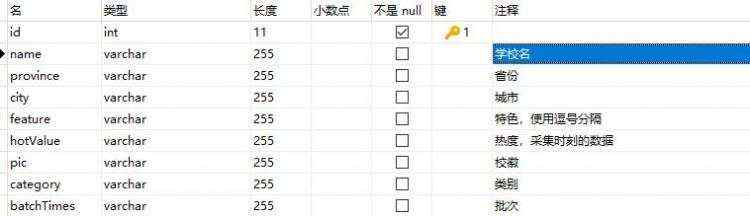
接下来编写数据解析函数和数据入库函数,代码如下所示。
def format_data(data):
"""
数据解析函数
:return:
"""
finished = data["data"]["finished"]
if finished:
return -1
else:
ret_list = data["data"]["list"]
school_list = []
for item in ret_list:
province = item["province"]
city = item["city"]
name = item["name"]
batchTimes = item["batchTimes"]
pic = item["pic"]
feature = ",".join(item["feature"])
hotValue = item["hotValue"]
category = item["category"]
school_list.append((name, province, city, feature, hotValue, pic, category, batchTimes))
insert_mysql(school_list)
上述代码无特殊部分,仅数据采集结束时,返回了状态值 -1,该值用于后续在主函数进行判断使用。
数据入库代码,使用 cursor.executemany(),函数编码如下所示。
def insert_mysql(schools):
"""
插入MySQL数据
:return:
"""
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='root',
database='playground',
charset='utf8'
)
cursor = conn.cursor()
sql = "insert into school_list(name,province,city,feature,hotValue,pic,category,batchTimes)values(%s,%s,%s,%s,%s,%s,%s,%s)"
affect_rows = cursor.executemany(sql, schools)
conn.commit()
cursor.close()
conn.close()
运行代码,可以将首页数据插入到表格中,共采集到 30 条数据,在 MySQL 表中查阅如下。
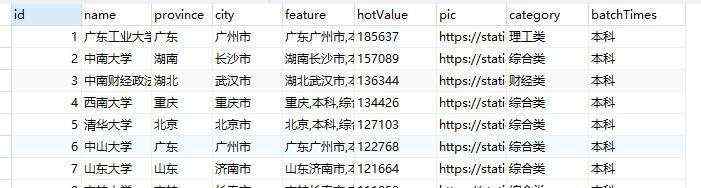
最后一步,将刚刚的代码扩展到全量数据,即【死循环】实现数据采集。
if __name__ == '__main__':
flag = True
index = 1
while flag:
ret = get_gaokao_data(index)
index += 1
if ret == -1:
flag = False
运行几秒钟之后,可以得到完整数据,最后的结果是 2760 所学校。
这些数据,最后将发布到 pachong.vip,大家可以交流学习使用。
📢📢📢📢📢📢
💗 你正在阅读 【梦想橡皮擦】 的博客
👍 阅读完毕,可以点点小手赞一下
🌻 发现错误,直接评论区中指正吧
📆 橡皮擦的第 804 篇原创博客
从订购之日起,案例 5 年内保证更新
- ⭐️ Python 爬虫 120,点击订购 ⭐️
- ⭐️ 爬虫 100 例教程,点击订购 ⭐️





![python的交互模式怎么输出名文汉字[python常见问题]](https://img1.php1.cn/3cd4a/24cea/978/9f39a0b333a15215.gif)





 京公网安备 11010802041100号
京公网安备 11010802041100号